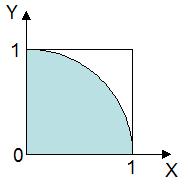また,最尤法と対比してみます。最尤法で系統樹を測る尺度となっている尤度ですが, これはある樹形(仮定)に沿って遺伝子が進化したときに,現在の遺伝子配列のセットが実現する確率を表します。 遺伝子の進化には無数の可能性が考えられますから,現在の配列データが実現する確率は極めて低いものになります。 一方で,ベイズ法における事後確率は,尤度と逆の発想になっています。尤度が「仮定→データ」の確率だとすると, 事後確率は「データ→仮定」の確率,すなわち手元にある遺伝子の配列, アラインメントのデータの原因が,ある系統樹である確率と言えます。
具体的な例を挙げて考えて見ましょう。 ここでは系統樹の作成ではなく,植物の同定を最尤法,あるいはベイズ推論を用いてすることを考えます。 さて,ある公園で見つけた花 X の名前を調べるとします。花 X は以下のような特徴を持っていました (長さについては四捨五入した値とします)。
| 形質 | 特徴 | |
|---|---|---|
| A | 花弁の長さ | 5 cm |
| B | 花弁の数 | 10 枚 |
| C | 雄蕊 | 2 cm |
| D | 色 | 赤色 |
| E | 雌蕊 | 5 裂 |
単純に考えるため,花 X は種(しゅ)P,Q,R のいずれかであるとします。 種 P〜R については各形質を持っている確率だけがわかっています。 例えば,種 P の花弁の長さが 3 cm である確率は 10 %,4 cm の確率は 15 %,5cm の確率は 50 % ・・・, といった感じです。問題になるのは,花 X と同じ形質を持っている確率だけなので,以下にその確率の表を示します。 (花弁の長さであれば,5 cm である確率,つまり 50 %)。
| 形質の状態 | 種 P | 種 Q | 種 R | |
|---|---|---|---|---|
| A | 花弁が 5 cm | 50 % | 30 % | 30 % |
| B | 花弁が 10 枚 | 30 % | 90 % | 0 % |
| C | 雄蕊が 2 cm | 30 % | 40 % | 30 % |
| D | 色が赤色 | 100 % | 90 % | 90 % |
| E | 雌蕊が 5 裂 | 50 % | 90 % | 90 % |
| 尤度 | 2.3 % | 8.7 % | 0 % | |
最下段に示した尤度はこの場合,各種について全ての形質が花 X と同じである確率で, 各形質の確率を積算することで求められます(種 P の場合は 50 % × 30 % × 30 % × 100 % × 50 % = 2.3 %)。 つまり,種 P の 2.3 % が花 X と区別できず,種 Q の 8.7 % が花 X と区別できない,ということです。 ちなみに種 R は花弁の枚数で確実に花 X と区別できるため,尤度が 0 % になっています。 図にすると下図の赤い部分の割合が(花 X が各種である)尤度ということになります。
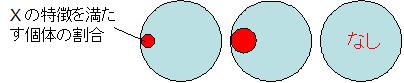
ここで,尤度が最も高いのは種 Q の場合ですから,最尤法の考え方に従うと, 花 X は種 Q と考えるのが最も尤もらしい(もっともらしい)推論として採用されることになります。 これは一つの考え方ですが,場合によっては最尤法の考え方がふさわしくない場合があります。
事後確率の考え方で上の例のを考えて見ましょう。ここでは,花 X が見つかった公園に, 種 P,Q,R がどれくらいの個体数あるのかが事前にわかっていたものとします(下図)。

この例の場合,今示した頻度の割合を事前確率と呼びます。 それぞれの種に事前確率をかけた値は,全体の中で例えば種 P であって花 X と同じ特徴を持った個体の割合になります。 言い換えると,公園の中で 100 本花があったときに,花 X と同じ特徴を持った種 P の花は,1.8 本存在すると言えます (2.3 % × 78 % = 1.8 % なので)。同様に他の 2 種についても計算してみましょう(下図)。

この結果,花 X と同じ特徴を持った個体数は,種 Q よりも 種 P の方が大きいことがわかります(1.8 % > 0.17 %)。 もう少し考えると,花 X が種 P である確率が計算できることがわかります。 すなわち図の赤い面積の合計の中で,種 P に含まれている部分がどれくらいの割合なのかを計算すればいいわけです。 これは以下の計算式で計算され,事後確率と呼ばれる値になります。
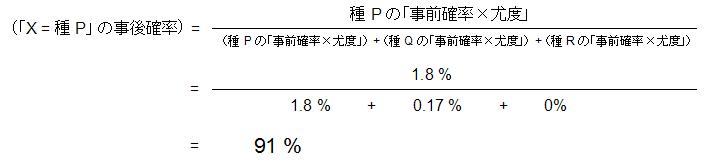
同様に他の 2 種についても事後確率を計算することが出来ます。
| 種 P | 種 Q | 種 R | |
|---|---|---|---|
| 事前確率 | 78 % | 2 % | 20 % |
| 尤度 | 2.5 % | 8.7 % | 0 % |
| 事前確率×尤度 | 2.0 % | 0.17 % | 0 % |
| 事後確率 | 91 % | 8.6 % | 0 % |
この結果から,花 X は 91 % の確率で種 P に同定され,種 Q の確率も 8.6 % ながら存在するが,種 R の確率はない, ということが言えます。これがベイズ推論の考え方です。 なお事前確率が全て等しい場合(種 P,Q,R ともに 33 % の場合), ベイズ推論での結果と最尤法で選ばれる結果は厳密に一致します。この例の場合,事前確率が等しければ,
| 種 P | 種 Q | 種 R | |
|---|---|---|---|
| 事前確率 | 33 % | 33 % | 33 % |
| 尤度 | 2.5 % | 8.7 % | 0 % |
| 事前確率×尤度 | 0.82 % | 2.9 % | 0 % |
| 事後確率 | 22 % | 78 % | 0 % |
となり,やはり花 X は種 Q である確率が一番高くなります。
さて,このベイズ推論を系統樹の推定に導入するとどうなるでしょうか? Huelsenbeck et al. (2001) に示された式を引用すると,あるデータの下でのある樹形が正しい確率(Pr[Tree | Data])は, 以下の形式で示されます。

ここで,Pr[Data | Tree] はその樹形の下での尤度で,Pr[Tree] はその樹形の事前確率になります (通常の系統解析では各樹形が出現する確率は平等と考え,全て同じ値にしています)。
さて,ここで問題になるのが Pr[Data] の値です。これは上で示した花の同定の例と同様に, 「事前確率×尤度」の総和になります。総和と書きましたが,これは花の場合には 3 種の候補についての和を求めただけで済みました。 しかし系統樹の場合には考えられる全ての樹形について計算しなければなりません。 しかも各樹形について枝の長さについて積分したり(連続値なので和ではありません), 塩基置換速度などのパラメータの値についても全て考慮しなければなりません。 当然ながらそのような値は計算できません。
これが,系統樹などに事前確率を導入するときの問題となっていました。 これを解決するために現在用いられているのが MCMC 法になります。
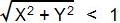 )の割合を数えれば,
扇形の面積の近似になると考えられます。
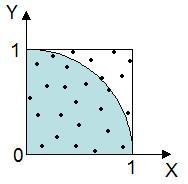
)の割合を数えれば,
扇形の面積の近似になると考えられます。